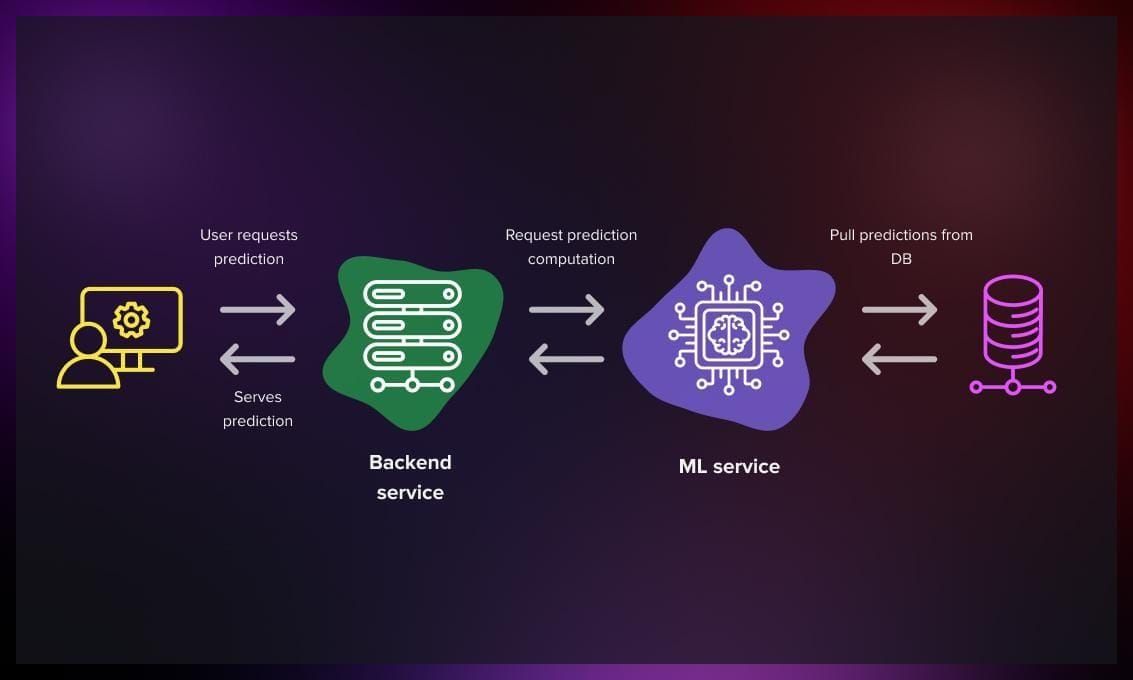
Introduction
Deploying machine learning (ML) models into production is a critical step in translating data science efforts into real-world impact. While developing an ML model is often the focus of data scientists, ensuring that the model performs reliably, scales effectively, and integrates seamlessly into business applications is equally important. Deployment involves moving a trained model from a development environment to a production system where it can serve predictions, often in real time, to end-users or other systems.
This article provides a detailed guide to ML model deployment, covering key strategies such as containerization, orchestration, and monitoring. We’ll explore popular tools, best practices, and practical examples to help you deploy models efficiently while addressing challenges like scalability, latency, and model drift. Whether you’re deploying a simple regression model or a complex deep learning system, this guide will equip you with the knowledge to succeed.
Understanding ML Model Deployment
Model deployment is the process of integrating a trained ML model into a production environment where it can process real-world data and deliver predictions. Unlike development, where the focus is on experimentation and accuracy, deployment prioritizes reliability, scalability, and performance. Key considerations include:
- Latency: Ensuring predictions are delivered quickly enough for the use case (e.g., real-time recommendations vs. batch processing).
- Scalability: Handling increased data volumes or user requests without performance degradation.
- Reliability: Ensuring the model remains accurate and stable over time.
- Maintainability: Enabling easy updates, monitoring, and retraining.
Deployment can take various forms, such as embedding models in applications, serving them via APIs, or running batch predictions. The choice depends on the use case, infrastructure, and business requirements.
Strategies for Model Deployment
1. Containerization
Containerization packages a model and its dependencies into a portable, lightweight unit called a container. Containers ensure consistency across development, testing, and production environments, reducing the “it works on my machine” problem.
Why Use Containers?
- Portability across cloud and on-premises systems.
- Isolation of dependencies, preventing conflicts.
- Simplified scaling and deployment.
Popular Tool: Docker Docker is the most widely used containerization platform. Here’s an example of containerizing a Python-based ML model using Docker:
# Dockerfile for a Flask-based ML model API
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY model.pkl app.py ./
EXPOSE 5000
CMD ["python", "app.py"]
# app.py: Flask API serving a pre-trained model
from flask import Flask, request, jsonify
import pickle
import numpy as np
app = Flask(__name__)
model = pickle.load(open('model.pkl', 'rb'))
@app.route('/predict', methods=['POST'])
def predict():
data = np.array(request.json['data'])
prediction = model.predict(data)
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
To build and run:
docker build -t ml-model-api .
docker run -p 5000:5000 ml-model-api
This creates a containerized Flask API serving predictions from a pre-trained model (e.g., saved as model.pkl).
2. Orchestration
Orchestration manages multiple containers to ensure scalability, fault tolerance, and efficient resource use. For ML models, orchestration handles load balancing, auto-scaling, and rolling updates.
Popular Tool: Kubernetes Kubernetes (K8s) is the leading orchestration platform. It manages containerized ML models across clusters, ensuring high availability and scalability.
Example Kubernetes deployment configuration:
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-model-deployment
spec:
replicas: 3
selector:
matchLabels:
app: ml-model
template:
metadata:
labels:
app: ml-model
spec:
containers:
- name: ml-model
image: ml-model-api:latest
ports:
- containerPort: 5000
Apply the deployment:
kubectl apply -f deployment.yaml
Kubernetes ensures three replicas of the model API are running, automatically scaling or restarting them as needed.
3. API-Based Deployment
Serving models via REST or gRPC APIs is a common approach, enabling integration with web applications or microservices. Tools like Flask, FastAPI, or TensorFlow Serving simplify this process.
Example with FastAPI:
# fastapi_app.py
from fastapi import FastAPI
import numpy as np
import pickle
app = FastAPI()
model = pickle.load(open('model.pkl', 'rb'))
@app.post("/predict")
async def predict(data: list):
input_data = np.array(data)
prediction = model.predict(input_data)
return {"prediction": prediction.tolist()}
Run with:
uvicorn fastapi_app:app --host 0.0.0.0 --port 8000
FastAPI provides automatic documentation and high performance, making it ideal for production APIs.
4. Batch Processing
For use cases like daily reports or large-scale data analysis, batch processing is more suitable than real-time APIs. Tools like Apache Airflow or AWS Batch can schedule and manage batch jobs.
Example with Pandas for batch predictions:
import pandas as pd
import pickle
# Load model and data
model = pickle.load(open('model.pkl', 'rb'))
data = pd.read_csv('batch_data.csv')
# Predict
predictions = model.predict(data.values)
data['predictions'] = predictions
data.to_csv('batch_results.csv', index=False)
This script processes a CSV file in batch, saving predictions to a new file.
Monitoring and Maintenance
Once deployed, models require continuous monitoring to ensure performance and accuracy. Key aspects include:
- Performance Monitoring: Track latency, throughput, and resource usage using tools like Prometheus and Grafana.
- Model Drift: Detect changes in data distribution that degrade model performance. Use statistical tests or tools like Evidently AI.
Example with Evidently for drift detection:
from evidently.pipeline.column_mapping import ColumnMapping
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
# Reference and current data
reference_data = pd.read_csv('reference_data.csv')
current_data = pd.read_csv('current_data.csv')
# Generate drift report
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=reference_data, current_data=current_data)
report.save_html('drift_report.html')
- Logging: Use tools like ELK Stack or CloudWatch to log predictions and errors.
- Retraining Pipelines: Automate retraining with tools like MLflow or Kubeflow when drift is detected.
Advanced Deployment Scenarios
1. Serverless Deployment
Serverless platforms like AWS Lambda or Google Cloud Functions allow deployment without managing servers, ideal for low-traffic or event-driven models.
Example with AWS Lambda (simplified):
import json
import pickle
import numpy as np
# Load model in memory (e.g., from S3)
with open('model.pkl', 'rb') as f:
model = pickle.load(f)
def lambda_handler(event, context):
data = np.array(json.loads(event['body'])['data'])
prediction = model.predict(data)
return {
'statusCode': 200,
'body': json.dumps({'prediction': prediction.tolist()})
}
2. Edge Deployment
For IoT or mobile applications, models are deployed on edge devices using frameworks like TensorFlow Lite or ONNX Runtime.
Example with TensorFlow Lite:
import tensorflow as tf
import numpy as np
# Load TFLite model
interpreter = tf.lite.Interpreter(model_path='model.tflite')
interpreter.allocate_tensors()
# Get input/output details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Predict
input_data = np.array([[1.0, 2.0]], dtype=np.float32)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
print(output_data)
3. A/B Testing and Canary Deployments
To evaluate new models, deploy them alongside existing ones (A/B testing) or gradually roll them out (canary deployments) using tools like Kubernetes or AWS ECS.
Best Practices
- Version Control: Use MLflow or DVC to version models and datasets.
- Security: Secure APIs with authentication (e.g., OAuth) and encrypt sensitive data.
- Testing: Validate model outputs in staging environments before production.
- Scalability: Design for horizontal scaling using load balancers and auto-scaling groups.
- Documentation: Maintain clear documentation for APIs and deployment pipelines.
Tools Overview
- Containerization: Docker, Podman
- Orchestration: Kubernetes, Docker Swarm
- API Frameworks: Flask, FastAPI, TensorFlow Serving
- Monitoring: Prometheus, Grafana, Evidently
- Workflow Management: Apache Airflow, Kubeflow
- Serverless: AWS Lambda, Google Cloud Functions
- Edge: TensorFlow Lite, ONNX Runtime
Real-World Example: E-Commerce Recommendation System
Consider deploying a recommendation model for an e-commerce platform:
- Model Training: Train a collaborative filtering model using scikit-learn or TensorFlow.
- Containerization: Package the model in a Docker container with FastAPI.
- Orchestration: Deploy on Kubernetes with three replicas for high availability.
- API: Serve recommendations via
/recommendendpoint, accepting user IDs and returning product suggestions. - Monitoring: Use Prometheus to track API latency and Evidently to detect drift in user behavior.
- Retraining: Schedule retraining with Airflow when drift exceeds a threshold.
Conclusion
Deploying machine learning models is a multifaceted process requiring careful planning and robust tools. Containerization with Docker ensures portability, while orchestration with Kubernetes enables scalability. Monitoring tools like Prometheus and Evidently maintain model reliability, and frameworks like FastAPI or TensorFlow Serving simplify API development. By adopting best practices and leveraging the right tools, you can deploy models that are efficient, scalable, and impactful.
For further exploration, check out documentation for Docker, Kubernetes, or MLflow, and consider experimenting with a small model deployment to gain hands-on experience. As ML adoption grows, mastering deployment will be key to delivering value in production environments.
Comments
No comments yet. Be the first to share your thoughts!